
 Welcome to Types of Tables in SAP tutorial. This tutorial is part of our free SAP ABAP training and we will provide an overview of different types of tables in SAP and explain their applications.
Welcome to Types of Tables in SAP tutorial. This tutorial is part of our free SAP ABAP training and we will provide an overview of different types of tables in SAP and explain their applications.
As it was stated in the previous tutorial, database objects stored in ABAP Data Dictionary comprise of database tables and views. In this tutorial let us discuss types of tables in SAP.
Tables in SAP can be categorized by several criteria, one of the most important of which is table category. In terms of category all tables are divided into:
- Transparent tables
- Pooled tables
- Cluster tables
Tables categories will be discussed further in more detail. Another classification criterion is data class. By data class tables are divided into:
- APPL0 or master data. This tables comprise all data that is changed very infrequently. For example, company codes, plants, distribution channels, et cetera.
- APPL1 or transaction data. Highly dynamic data, that is changed a lot. The example of such data can be exchange rates updates, MRP requirements values and so on.
- APPL2 or organizational data. This is a customizing data, which hold system’s settings, like ISO codes, currency names and others. Usually they are TXXX tables.
- USR and USR1 are customer data. USR is a table namespace dedicated for user and customer developments, i.e. Z_ and Y_ tables.
- DDIM or dimensional tables. Applicable only to BW.
- DFACT or facts tables. Applicable only to BW.
The following illustration depicts relation between table data class and how it is stored on database level.
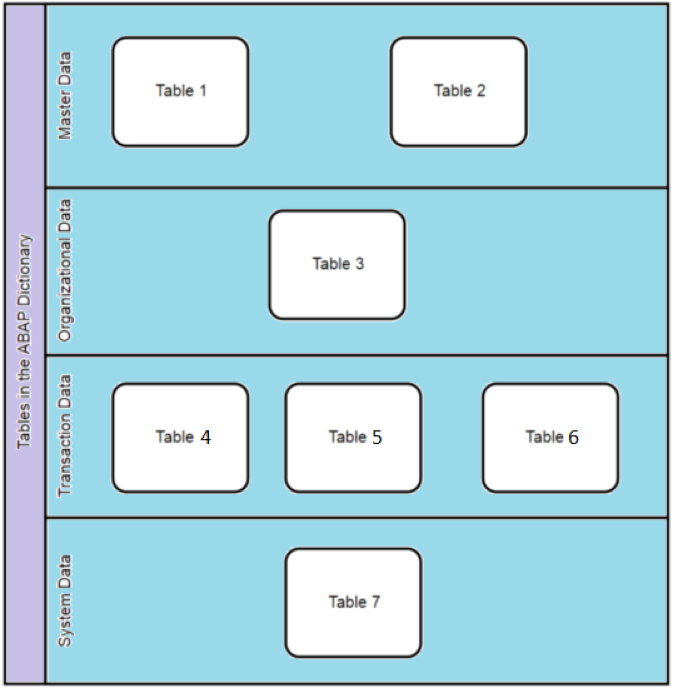
Size category is also a criterion for types of tables in SAP, which denotes how much memory is allocated to a table by SAP. Tables can have the following size categories:
| Size Category | Expected Rows |
| 0 | 0 to 1,000 |
| 1 | 1,000 to 4,200 |
| 2 | 4,200 to 17,000 |
| 3 | 17,000 to 68,000 |
| 4 | 68,000 to 270,000 |
| 5 | 270,000 to 540,000 |
| 6 | 540,000 to 1,000,000 |
| 7 | 1,000,000 to 2,100,000 |
| 8 | 2,100,000 to 4,300,000 |
| 9 | 4,300,000 to 170,000,000 |
However, the above values can vary depending on different database back-ends and depending on memory provision.
Transparent Tables
Transparent table is the main table category and thus deserves a detailed explanation. All in all, it is a fundamental concept in SAP data storage, which is observed across all SAP projects.
What makes table transparent and how it is relevant to other table categories?
The key point that one should know about transparency of SAP table is a 1:1 mapping. To put it another way, each transparent table exists with the same structure both in ABAP Data Dictionary as well as on the database level exactly with the same data and fields and exactly one database table per one SAP table.
Graphically it can be showed as follows:
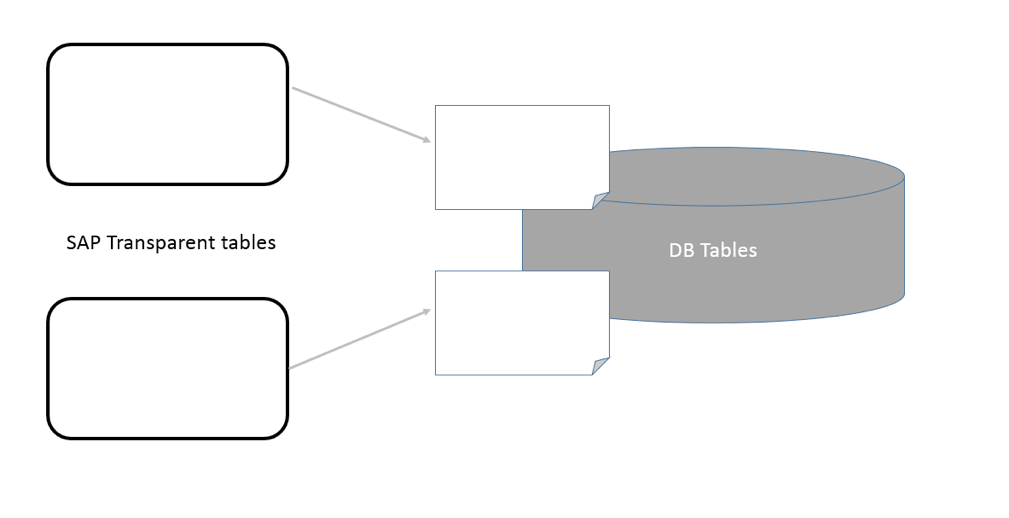
Transparent table data can be accesses and manipulated using OpenSQL and Native SQL, unlike pooled and cluster tables. Also, the data can be accessed outside of AS (Application Server) ABAP in a native database interface.
Saving and activation of a transparent table is equivalent to SQL DDL statement CREATE TABLE on a relevant database backend.
Pooled Tables
Pooled tables (or table pool) is another special category of tables in ABAP Data Dictionary. What is intended for?
Pooled tables are used primarily for storing many small objects like texts, screen sequences, temporary data, and do on. It is NOT recommended to create them manually and of course not recommended to save business data in pooled tables.
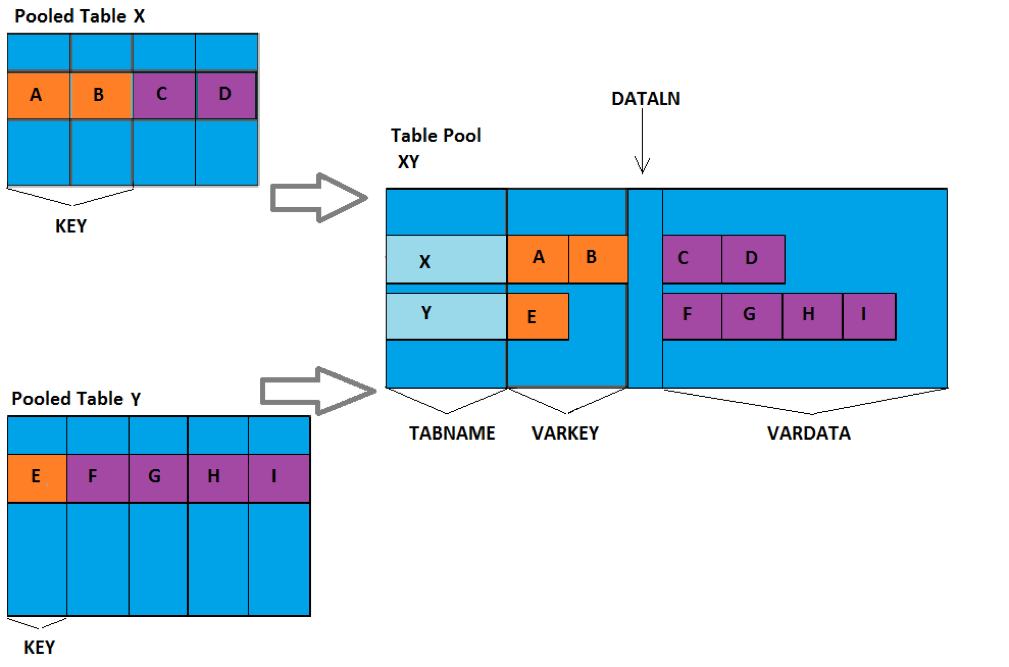
Technically, it works like this: data from several tables is stored together in a table pool, which is defined on the database level. All tables in a table pool are not tables per se, but just records in a pool. Pool is a database table of following structure:
| Field | Data type | Description |
| Tabname | CHAR(10) | Name of a pooled table |
| Varkey | CHAR (n) | All primary key fields of the pooled table record in a string form. The maximum length for n is 110. |
| Dataln | INT2(5) | Length of the string in Vardata |
| Vardata | RAW (n) | All data fields of the pooled table record in a string form. |
Every time you create and save a pooled table to ABAP Data Dictionary, the system just puts that record in a pool and all data fields of a pooled table will be put in the Vardata field of the table pool. Nothing is really created in backend, unlike with the transparent table.
The following scheme depicts how pooled tables are stored in the database backend.
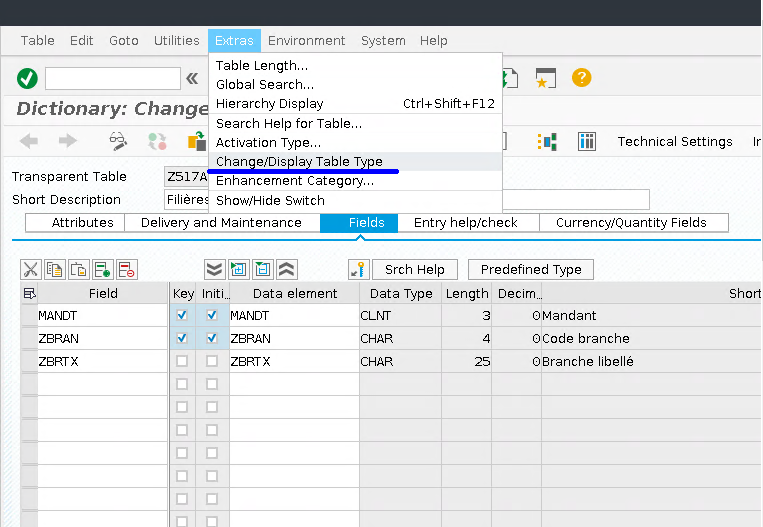
One big difference of a pooled table from the transparent one that it cannot be created directly. One who wishes to create a pooled table needs to create a pool beforehand, then create a table of a transparent type, and only then change its type to pooled. Transforming a transparent table to a pooled is done in SE11 transaction and includes assignment of it to the pool and adding correspondent record to it. It is done in ABAP Data Dictionary via Extras->Change/Display Table Type menu as shown below.
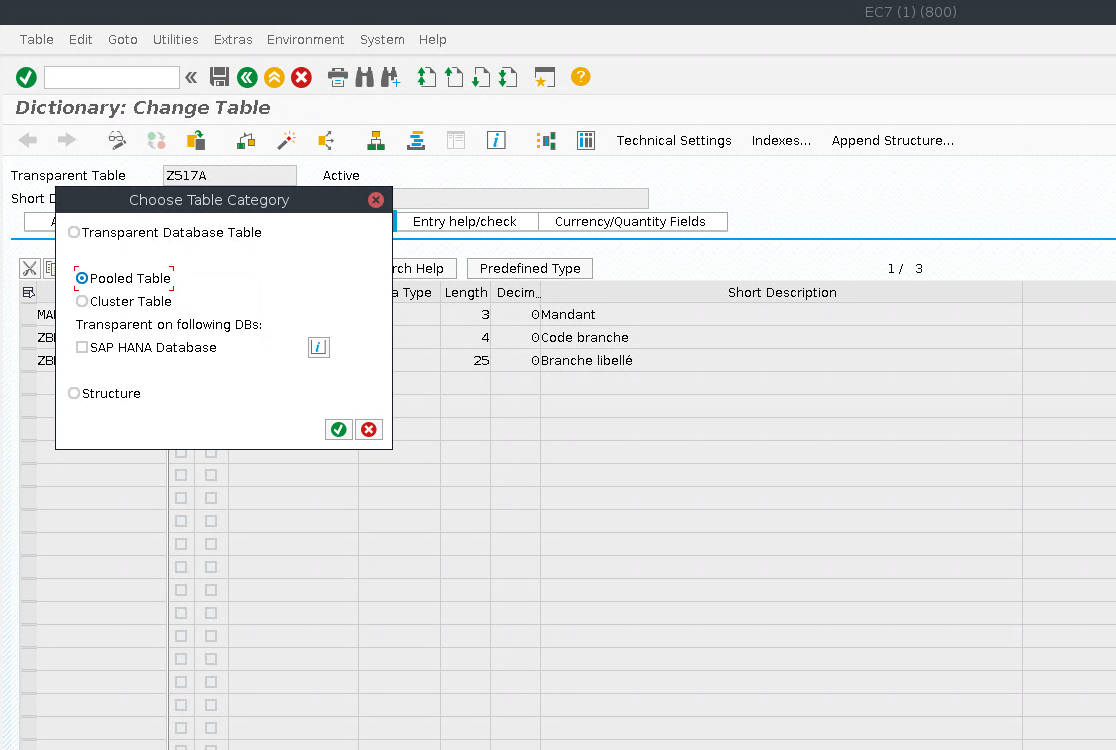
Cluster Tables
Clustered table is another interesting table type, which, similarly to pooled tables, has no physical representation on the database level. It is just a record in a table cluster which contain common keys of all tables constructing this clustered table. Cluster table is intended primarily for acceleration of simultaneous access to tables that have common fields in their keys.
The principle of creation of a cluster table is similar to the pooled table creation. One cannot create cluster table directly but rather should create a cluster beforehand, and then transform a transparent table to a clustered one by assigning it to the cluster.
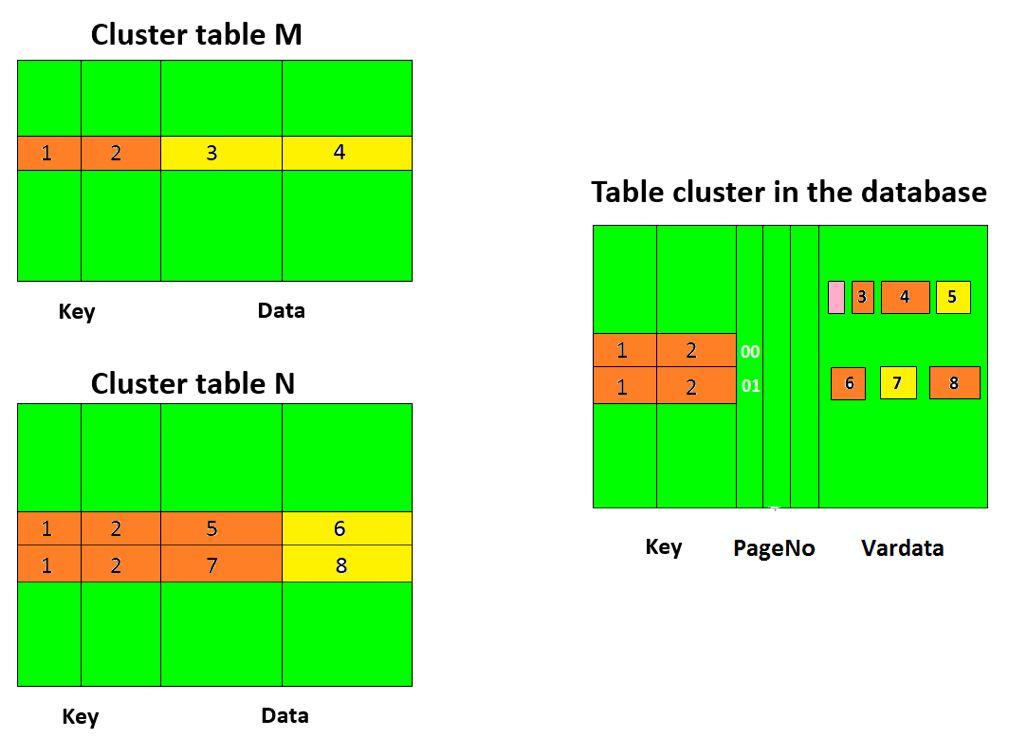
So, what is a table cluster? It is a physical table containing all rows of the tables assigned to it. Table cluster structure on the database level is shown below.
| Field | Type | Description |
| CLKEY1 | * | First key field |
| CLKEY2 | * | Second key field |
| … | … | … |
| CLKEYn | * | nth key field |
| Pageno | INT2(5) | Number of the continuation record |
| Timestamp | CHAR(14) | Timestamp |
| Pagelg | INT2(5) | Length of the Vardata value |
| Vardata | RAW (n) | Data fields of a cluster tables in a string form. |
One physical record in a table cluster can correspond to several logical data records in different clustered tables. Thus, the records of all cluster tables with the same table key are stored under a single key in the cluster. The values of these key fields are stored to the designated key fields of a cluster (CLKEY1, CLKEY2), and the values of all data fields of the assigned clustered tables are written to Vardata field. If the resulting string exceeds the maximum Vardata field length, the remainder is put into a continuation record.
A simple representation of a table cluster is shown below.
A good example of a cluster table is BSEG. It is not actually a database table but rather an intersection (cluster) of six tables:
- BSIS/BSAS – open/cleared items for G/L
- BSIK/BSAK – for vendors
- BSID/BSAD – for customers
Conclusion
Now, let’s wrap up and make a table that facilitates easy comparison of different types of tables in SAP. The properties of these types are summarized below.
| Transparent | Pool | Cluster | |
| Physical representation | Contains a single table | Many small tables | Few common-key logical tables |
| Relationship to DB table | One-to one relationship | Many-to-one relationship | Many-to-one relationship |
| DB structure correspondence | The database table has the same name, same number of fields and the fields have the same names | Pooled table have different name, number of fields and their numbers ae different. | Cluster table have different name, number of fields and their numbers ae different. |
| Primary key | Single primary key | Primary key of each table in a pool is different | Primary key of each cluster table in cluster is similar |
| Indices | Secondary indices can be created | Secondary indices cannot be created | Secondary indices cannot be created |
| SQL | Can be accessed both with OpenSQL and NativeSQL | Can be accessed with OpenSQL only | Can be accessed with OpenSQL only |
| Creation method | Automatic, via SE11 | Pool should be created explicitly | Cluster should be created explicitly |
| Use-case | Storing master data, transactional data and custom user data | Improving resource utilization while accessing a big set of small tables simultaneously | Used when the tables have primary key fields in common and these tables are accessed simultaneously |
—
Did you like this tutorial? Have any questions or comments? We would love to hear your feedback in the comments section below. It’d be a big help for us, and hopefully it’s something we can address for you in improvement of our free SAP ABAP tutorials.
Navigation Links
Go to next lesson: How to Create Tables in SAP
Go to previous lesson: SAP ABAP Data Dictionary
Go to overview of the course: SAP ABAP Training
Good tutorial. Each table category is explained very clearly with examples. It helped me understand the concepts better
Although I like the expalantions, it is time for,an update: your examples are not up to date anymore with respect to S/4HANA developments. At least you should also extend with a chapter about CDS compatibility views. See this comment as encouraging, not as a breakdown.
Hello,
while I am completely agree that this tutorial does not cover HANA backend, I’d rather treat it as a separate topic, as HANA have significant architectural differences from other SAP database backends. Separate tutorial dedicated to HANA is coming soon.
nice explanation